Vamos a programar #52 - Introducción al paralelismo (Básico)
Hola de nuevo a todos, el día de hoy vamos a ver cómo es que se usan las clases en .NET para poder usar el paralelismo.
Antes que nada, ¿que es el paralelismo?
Todas las tareas las hacia de forma secuencial (una tras la otra), pero si el hardware puede hacer más, ¿porque no explotarlo cómo se debe? Actualmente los lenguajes de programación de .NET, disponen de una clase que ayuda a la hora de crear los procesos paralelos.
Para darnos una idea de cómo implementarlo, veamos el siguiente código.
Para poder usar las funciones de paralelismo, debemos de importar el espacio System.Threading.Tasks. El código simplemente calcula el número MD5 de un archivo, pero si no fijamos con detenimiento en BtnParallel_Click, veremos que hacemos uso de Parallel.For , que en su forma más simple, recibe 3 argumentos. El primero, es un valor del tipo int que servirá para indicar desde que número empezaremos la iteración, en este caso es el número 0 (porque desde ahí vamos a empezar a contar). El siguiente parámetro, también es un valor del tipo int, que se usará cómo limite para la iteración, en el caso del código anterior, indicamos que solo va a llegar hasta ItemCount que almacena el número de elementos que contiene un arreglo. Finalmente viene la acción, en este caso la creamos por medio de una expresión lambda en la cual decimos que por cada elemento, se va llamar a la función GetMd5, y a su vez el valor resultante se asignará a un elemento de la matriz HASH2, cuando termine el proceso, todos los valores se agregaran al listview principal y se mostrarán al usuario.
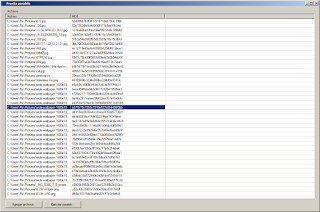
Los resultados los podemos ver en la siguiente imagen (hablando de rendimiento).


Mientras que de un lado tenemos que el uso del CPU está en 25% y tardo 30 segundos en calcular el HASH de algunas imágenes, del otro vemos que el uso del CPU es al 100% y además el tiempo que le tomo fue una cuarta parte del tiempo del calculo secuencial.
Para que revises bien el código, lo pongo en mi dropbox cómo de costumbre, pero cabe aclarar que es meramente ilustrativo, pero cómo introducción funciona. En futuros post veremos cómo hacer uso de las sobrecargas que tienen la misma función Parallel.for, pero además veremos cuales son las diferencia con el multi-therad tradicional (recuerdo que hice un post pero no se publicó y desapareció).
Los leo luego

Antes que nada, ¿que es el paralelismo?
El paralelismo es una forma de computación en la cual varios cálculos pueden realizarse simultáneamente, basado en el principio de dividir los problemas grandes para obtener varios problemas pequeños, que son posteriormente solucionados en paralelo. Hay varios tipos diferentes de paralelismo: nivel de bit, nivel de instrucción, de datos y de tarea. El paralelismo ha sido empleado durante muchos años, sobre todo para la Computación de alto rendimiento. Wikipedia/paralelismo.Aplicado a los términos de la programación tradicional, el paralelismo significa crear varias tareas que se ejecutan de forma simultanea, en el caso de los sistemas de computo moderno, la gran mayoría de ellos disponen de más de un procesador (9~12 núcleos en el mejor de los casos para el computo casero), pero a la hora de hacer cálculos, al menos en mi caso, nunca me preocupe por usar el mayor poder de computo disponible.
Todas las tareas las hacia de forma secuencial (una tras la otra), pero si el hardware puede hacer más, ¿porque no explotarlo cómo se debe? Actualmente los lenguajes de programación de .NET, disponen de una clase que ayuda a la hora de crear los procesos paralelos.
Para darnos una idea de cómo implementarlo, veamos el siguiente código.
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Diagnostics;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.IO;
using System.Security.Cryptography;
using System.Threading.Tasks;
namespace PruebaParalelo
{
public partial class FrmMain : Form
{
private FileInfo[] Archivos;
private string GetMd5(string filename)
{
StringBuilder SBuild = new StringBuilder();
using (var md5 = MD5.Create())
{
using (var stream = File.OpenRead(filename))
{
byte[] Data = md5.ComputeHash(stream);
for (int i = 0; i < Data.Length; i++)
{
SBuild.Append(Data[i].ToString("x2"));
}
return SBuild.ToString();
}
}
}
public FrmMain()
{
InitializeComponent();
}
private void BtnAddFiles_Click(object sender, EventArgs e)
{
string Path;
using(FolderBrowserDialog FolderDialog = new FolderBrowserDialog())
{
FolderDialog.Description = "Selecciona un folder con archivos";
if (FolderDialog.ShowDialog() == System.Windows.Forms.DialogResult.OK)
{
Path = FolderDialog.SelectedPath;
DirectoryInfo di = new DirectoryInfo(Path + "\\");
Archivos = di.GetFiles("*.*", SearchOption.AllDirectories);
foreach (FileInfo Archivo in Archivos)
{
LVFiles.Items.Add(Archivo.FullName);
}
}
}
}
private void BtnParallel_Click(object sender, EventArgs e)
{
string[] HASH2;
int ItemCount = Archivos.Length;
HASH2 = new string[Archivos.Length];
int j = 0;
try
{
Parallel.For(0, ItemCount, (i) =>
{
HASH2[i] = GetMd5(Archivos[i].FullName);
}
);
foreach (FileInfo Archivo in Archivos)
{
LVFiles.Items[j].SubItems.Add(HASH2[j]);
j++;
}
}
catch
{
}
}
}
}
Para poder usar las funciones de paralelismo, debemos de importar el espacio System.Threading.Tasks. El código simplemente calcula el número MD5 de un archivo, pero si no fijamos con detenimiento en BtnParallel_Click, veremos que hacemos uso de Parallel.For , que en su forma más simple, recibe 3 argumentos. El primero, es un valor del tipo int que servirá para indicar desde que número empezaremos la iteración, en este caso es el número 0 (porque desde ahí vamos a empezar a contar). El siguiente parámetro, también es un valor del tipo int, que se usará cómo limite para la iteración, en el caso del código anterior, indicamos que solo va a llegar hasta ItemCount que almacena el número de elementos que contiene un arreglo. Finalmente viene la acción, en este caso la creamos por medio de una expresión lambda en la cual decimos que por cada elemento, se va llamar a la función GetMd5, y a su vez el valor resultante se asignará a un elemento de la matriz HASH2, cuando termine el proceso, todos los valores se agregaran al listview principal y se mostrarán al usuario.
Los resultados los podemos ver en la siguiente imagen (hablando de rendimiento).


Mientras que de un lado tenemos que el uso del CPU está en 25% y tardo 30 segundos en calcular el HASH de algunas imágenes, del otro vemos que el uso del CPU es al 100% y además el tiempo que le tomo fue una cuarta parte del tiempo del calculo secuencial.
Para que revises bien el código, lo pongo en mi dropbox cómo de costumbre, pero cabe aclarar que es meramente ilustrativo, pero cómo introducción funciona. En futuros post veremos cómo hacer uso de las sobrecargas que tienen la misma función Parallel.for, pero además veremos cuales son las diferencia con el multi-therad tradicional (recuerdo que hice un post pero no se publicó y desapareció).
Los leo luego










No hay comentarios.