Vamos a programar #104 - Leyendo metadatos de archivos FLAC (Pt. 3 Ver. C#)
Hola de nuevo a todos, el día de hoy vamos a continuar con la última parte de FlacTagReader.

En el post anterior vimos cómo es que funcionan algunas funciones (valga la redundancia) y hoy veremos las faltantes.
La siguiente función es: "NumberToBlockType()". Esta función sirve para convertir un número en su equivalente al de la numeración "BlockTypes". Recibe un parámetro del tipo "uint" que es el número que queremos convertir. Regresa un valor del tipo enumeración "BlockTypes" equivalente. Hay que recordar que nos basamos en la de los tipos de bloques de la documentación.
La siguiente función es: "ReadVorbisData()". Cómo su nombre lo podría sugerir, esta función sirve para leer los datos de tipo vorbis ¿Qué es esto? te preguntaras, este bloque en particular es el que contiene los metadatos tales cómo: álbum, artista, año, etc. Siguen la estructura para los comentarios en archivos ogg vorbis.
La estructura de los comentarios es cómo la que sigue:
- Tamaño de la descripción del proveedor (32 bits).
- Cadena de texto para describir al proveedor.
- Tamaño de la lista de comentarios del usuario (32 bits).
- Tamaño de la lista de comentarios.
- Tamaño del elemento actual.
- Cadena de texto en formato UTF-8
- Marcador de final del bloque (si es verdadero o no hay se marca error o fin del bloque).
- Nombre del campo.
- = (símbolo de igual o símbolo ASCII 0x3D).
- Descripción del campo.
- Los nombres de cada campo no deben de contener símbolos que escapen del estándar ASCII de caracteres imprimibles, es decir: de 0x20 a 0x7D (excluyendo el símbolo de igual "=" o 0x3D) y de 0x41 a 0x5A.
- Se pueden usar los siguientes nombres de campo:
- TITLE
- VERSION
- ALBUM
- TRACKNUMBER
- ARTIST
- PERFORMER
- COPYRIGHT
- LICENSE
- ORGANIZATION
- DESCRIPTION
- GENRE
- DATE
- LOCATION
- CONTACT
- ISRC
- Aunque los campos anteriores son sugeridos, podemos usar los propios (sin abusar de ello) y por ejemplo, un campo llamado BEATPERMINUTE, es totalmente válido.

Vamos a programar #103 - Leyendo metadatos de archivos FLAC (pt 2. Ver c#)
Hola de nuevo a todos. El día de hoy vamos a continuar con mas de los archivos FLAC y sus metadatos.

using System; using System.Drawing; using System.IO; using System.Text; using System.Threading; using System.Threading.Tasks; using System.Windows.Forms; namespace FLACTagReader { public partial class Form1 : Form { // 0 : STREAMINFO 0000000 // 1 : PADDING 0000001 // 2 : APPLICATION 0000010 // 3 : SEEKTABLE 0000011 // 4 : VORBIS_COMMENT 0000100 // 5 : CUESHEET 0000101 // 6 : PICTURE 0000110 // 7-126 : reserved 1111000 - Invalid // 127 : invalid, to avoid confusion with a frame sync code /// <summary> /// Enumeración con los posibles bloques contenidos en un archivo FLAC /// </summary> private enum BlocksTypes { /// <summary> /// Bloque mandatorio con la información del Stream /// </summary> Block_Type_StreamInfo = 0, /// <summary> /// Bloque de Padding /// </summary> Block_Type_Padding = 1, /// <summary> /// Bloque con la informacion de la aplicación /// </summary> Block_Type_Application = 2, /// <summary> /// Bloque Seektable /// </summary> Block_Type_SeekTable = 3, /// <summary> /// Bloque con metadatos /// </summary> Block_Type_VorbisComment = 4, /// <summary> /// Bloque con cuesheet /// </summary> Block_Type_CueSheet = 5, /// <summary> /// Bloque con imagen /// </summary> Block_Type_Picture = 6, /// <summary> /// Bloque no válido /// </summary> Block_Type_NoValid = 7 } public Form1() { InitializeComponent(); } /// <summary> /// Crea una imagen a partir de una secuencia de bytes /// </summary> /// <param name="bytesArr">Matriz de bytes que contiene los datos de la imagen</param> /// <returns>Regresa una imagen</returns> public Image ByteArrayToImage(byte[] bytesArr) { using (MemoryStream memstr = new MemoryStream(bytesArr)) { Image img = Image.FromStream(memstr); return img; } } // 4 4 n*4 4 n*4 4 4 4 4 !4 !n*4 //<32>,<32>,<n*8>,<32>,<n*8>,<32>,<32>,<32>,<32>,<32>,<n*8> // 1 2 3 4 5 6 7 8 9 10 11 /// <summary> /// Lee todo los datos del bloque PICTURE y extrae la imagen contenida /// </summary> /// <param name="TheData">Arreglos bytes que contiene todo el bloque PICTURE</param> /// <returns>Regresa una imagen</returns> private Image ReadPictureData(byte[] TheData) { uint CurrentPos = 4;//1 uint CurrentSize = GetBlockSize(TheData, (int)CurrentPos, 4); CurrentPos += 4;//2 string MimeType = Encoding.ASCII.GetString(TheData, (int)CurrentPos, (int)CurrentSize); CurrentPos += CurrentSize;//3 CurrentSize = GetBlockSize(TheData, (int)CurrentPos, 4); CurrentPos += (CurrentSize + (4 * 5));//4-9 CurrentSize = GetBlockSize(TheData, (int)CurrentPos, 4); CurrentPos += 4; byte[] TempImage = new byte[CurrentSize]; Array.Copy(TheData, CurrentPos, TempImage, 0, CurrentSize); return ByteArrayToImage(TempImage); } /// <summary> /// Convierte un número en su valor equivalente al tipo de bloque /// </summary> /// <param name="Data"> /// Entero sin signo con la representacion del bloque</param> /// <returns>Regresa un valor de la enumeración <typeparamref name="BlockTypes"/>BlockTypes</returns> private BlocksTypes NumberToBlockType(uint Data) { switch (Data) { case 0: return BlocksTypes.Block_Type_StreamInfo; case 1: return BlocksTypes.Block_Type_Padding; case 2: return BlocksTypes.Block_Type_Application; case 3: return BlocksTypes.Block_Type_SeekTable; case 4: return BlocksTypes.Block_Type_VorbisComment; case 5: return BlocksTypes.Block_Type_CueSheet; case 6: return BlocksTypes.Block_Type_Picture; default: return BlocksTypes.Block_Type_NoValid; } } /// <summary> /// Lee el bloque con la informacion estructurada /// </summary> /// <param name="TheData">Arreglo de bytes del cual se extraera la información</param> /// <returns>Regresa un arreglo del tipo string con todos los campos que se encontraron</returns> private string[] ReadVorbisData(byte[] TheData) { uint NumberOfFields = 0; uint CurrentField = 1; uint CurrentPosition = 0; //Vendor uint CurrentSize = BitConverter.ToUInt32(TheData, (int)CurrentPosition); CurrentPosition += 4; byte[] CurrentChunk = new byte[CurrentSize]; Array.Copy(TheData, CurrentPosition, CurrentChunk, 0, CurrentSize); string Currenttext = Encoding.UTF8.GetString(CurrentChunk); CurrentPosition += CurrentSize; NumberOfFields = BitConverter.ToUInt32(TheData, (int)CurrentPosition); CurrentPosition += 4; string[] Fields = new string[NumberOfFields]; //CommentField while (CurrentField <= NumberOfFields) { CurrentSize = BitConverter.ToUInt32(TheData, (int)CurrentPosition); CurrentPosition += 4; byte[] CurrenUserCommentList = new byte[CurrentSize]; Array.Copy(TheData, CurrentPosition, CurrenUserCommentList, 0, CurrentSize); Currenttext = Encoding.UTF8.GetString(CurrenUserCommentList); CurrentPosition += CurrentSize; Fields[CurrentField - 1] = Currenttext; CurrentField += 1; } return Fields; } /// <summary> /// Obtiene el valor del bloque desde un byte /// </summary> /// <param name="Data">byte del cual se va a obtener la información</param> /// <returns>Regresa un valor que es equivalente al tipo de bloque</returns> private UInt32 GetBlockType(byte Data) { Data <<= 3; Data >>= 3; return Data; } /// <summary> /// Obtiene si el bloque es el último de la serie /// </summary> /// <param name="Data">byte del cual se obtendra la información</param> /// <returns>true si el bloque es el último, false en caso contrario</returns> private bool IsLastFrame(byte Data) { Data >>= 7; if (Data == 1) return true; else return false; } /// <summary> /// Obtiene el tamaño de un bloque /// </summary> /// <param name="Data">Arreglo de bytes que contiene el tamaño del bloque</param> /// <param name="StartIndex">Indica la posicion en donde se empezará a leer</param> /// <param name="Size">Indica el tamaño en bytes que se van a leer</param> /// <returns>Regresa el tamaño del bloque actual</returns> private UInt32 GetBlockSize(byte[] Data, int StartIndex, int Size) { byte[] CurrentData = new byte[4]; Array.Copy(Data, StartIndex, CurrentData, 0, Size); Array.Reverse(CurrentData); return BitConverter.ToUInt32(CurrentData, 0); } /// <summary> /// Obtiene el tamaño de un bloque /// </summary> /// <param name="Data">Arreglo de bytes que contiene el tamaño del bloque</param> /// <returns>Regresa el tamaño del bloque actual</returns> private UInt32 GetBlockSize(byte[] Data) { byte[] CurrentData = Data; //Ponemos el primer byte en 0 porque se usa para identificar el bloque //a la hora de convertir a UInt32 se esperan 4 bytes, pero este siempre será 0 u otro valor no relevante //para el tamaño del bloque CurrentData[0] = 0; Array.Reverse(CurrentData); return BitConverter.ToUInt32(CurrentData, 0); } /// <summary> /// Obtiene los datos de un bloque /// </summary> /// <param name="FileName">Nombre del archivo del cual se obtendra</param> /// <param name="TypeOfBlock">Tipo de bloque que se va a buscar</param> private void GetBlock(string FileName, BlocksTypes TypeOfBlock) { byte[] DataBuff; bool LastFrame = false; FileStream FS = new FileStream(FileName, FileMode.Open, FileAccess.Read, FileShare.Read); using (BinaryReader BR = new BinaryReader(FS, Encoding.ASCII)) { DataBuff = BR.ReadBytes(4); if (string.Equals(Encoding.ASCII.GetString(DataBuff), "fLaC", StringComparison.Ordinal)) { UInt32 CurrentBlockSize; UInt32 CurrentPosition = (UInt32)FS.Position; BlocksTypes CurrentBlockType = BlocksTypes.Block_Type_NoValid; while (!LastFrame) { //primer bloque siempre será Block_Type_StreamInfo DataBuff = BR.ReadBytes(4); LastFrame = IsLastFrame(DataBuff[0]); CurrentBlockType = NumberToBlockType(GetBlockType(DataBuff[0])); if (CurrentBlockType == TypeOfBlock) { if (TypeOfBlock == BlocksTypes.Block_Type_VorbisComment) { string[] Fields; CurrentBlockSize = GetBlockSize(DataBuff); Fields = ReadVorbisData(BR.ReadBytes((int)CurrentBlockSize)); textBox1.Clear(); for (int i = 0; i < Fields.Length; i++) { textBox1.Text += Fields[i] + " | "; } } else if (TypeOfBlock == BlocksTypes.Block_Type_Picture) { CurrentBlockSize = GetBlockSize(DataBuff); pictureBox1.Image = ReadPictureData(BR.ReadBytes((int)CurrentBlockSize)); } } else { CurrentBlockSize = GetBlockSize(DataBuff); FS.Seek(FS.Position + CurrentBlockSize, SeekOrigin.Begin); } } } else { MessageBox.Show("Archivo Flac no válido"); } } } private void button1_Click(object sender, EventArgs e) { using (OpenFileDialog OpDiag = new OpenFileDialog()) { OpDiag.Filter = "Archivos FLAC|*.flac|Todos los arhivos|*.*"; if (OpDiag.ShowDialog() == DialogResult.OK) { GetBlock(OpDiag.FileName, BlocksTypes.Block_Type_VorbisComment); GetBlock(OpDiag.FileName, BlocksTypes.Block_Type_Picture); pictureBox1.SizeMode = PictureBoxSizeMode.StretchImage; } } } } }
- <32> El tipo de imagen de acuerdo a la descripción de la etiqueta ID3 "APIC".
- <32> El tamaño de la descripción del tipo de archivo o MIME type.
- <n*8> Cadena de texto con la descripción del tipo de archivo.
- <32> El tamaño de la descripción de la imagen.
- <n*8> La descripción de la imagen en UTF8
- <32> El ancho de la imagen en píxeles
- <32> El alto de la imagen en pixeles.
- <32> La profundidad del color de la imagen en bits por pixel.
- <32> Para las imágenes con índice de color, el número de colores usados, para el resto 0.
- <32> El tamaño de los datos de la imagen.
- <n*8> Los datos de la imagen.

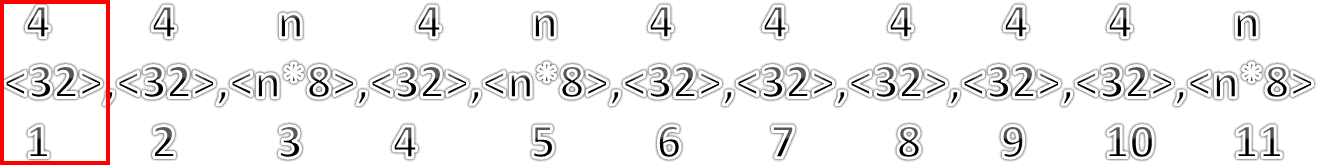




Vamos a programar #102 - Leyendo metadatos de archivos FLAC (pt.1)
Hola de nuevo a todos. El día de hoy vamos a continuar con más de los archivos FLAC.

En los post mas recientes hemos visto las cualidades de los archivos FLAC, pero además cómo crear los nuestros. Al igual que en MP3, existen metadatos embebidos en ellos, y sirven para describir algunos datos importantes tales cómo: el nombre de la canción, el artista, el nombre del álbum, el genero, etc.
Estructura de un archivo FLAC
La estructura de los archivos FLAC es totalmente diferente a la de un MP3 por lo que vale la pena revisarla por separado. Cada archivo FLAC consiste de cuatro partes principales:
- Una cadena de cuatro bytes con la secuencia "fLaC" (así tal cual se ve).
- Un bloque de metadatos con la información del "stream"
- Cero o mas bloques de metadatos.
- Uno o mas "frames" de audio.
Para mas detalles se puede revisar la página de xiph.org, donde esta la descripción completa para los archivos FLAC.
De las cuatro partes que se mencionan anteriormente, nos concentraremos en la segunda y tercera (Técnicamente las dos entran en el mismo conjunto, solo que la segunda es obligatoria, mientras que las subsecuentes son opcionales, hablando solamente de los bloques de metadatos), por lo que revisaremos cómo es que está compuesta cada una.
Pero antes una representación de cómo está estructurado el archivo:

Metadatos
- STREAM
- METADATA_BLOCK
- METADATA_BLOCK_HEADER (Encabezado)
- <1> Indicador de último bloque
- <7> Descriptor del tipo de bloque
- <24> Tamaño del bloque en bytes (BYTES!!!)
- 0: STREAMINFO
- Contiene información acerca de todo el archivo, este bloque es mandatorio y siempre será e primero de la secuencia después de la secuencia 0x66, 0x4c, 0x61, 0x43 (o de manera simple después de "fLaC" ).
- 1: PADDING
- Este tipo de bloque sirve cómo reserva y el contenido no representará nada, normalmente se llena con 0x00. Cuando se crea el archivo sin los metadatos completos, en lugar des escribir un archivo nuevo con los bloques nuevos, simplemente se reemplaza este bloque conservando el archivo original y agilizando la escritura del mismo.
- 2: APPLICATION
- Nombre de la aplicación que se uso para codificar el archivo, puede ser cualquiera que el usuario elija, aunque se recomienda el registro de la aplicación para obtener un ID único para cada quien.
- 3: SEEKTABLE
- Sirve cómo marcador para desplazarse en el archivo a la hora de la reproducción, aunque se puede omitir, se recomienda incluirlo para agilizar la lectura.
- 4: VORBIS_COMMENT
- Este bloque contiene la información relevante a los creadores del contenido multimedia y la descripción del mismo, se usa la especificación de "Vorbis comment"
- 5: CUESHEET
- Contiene información que se puede usar en un CD
- 6: PICTURE
- Imagen representativa del archivo, similar a la imagen embebida en un archivo MP3.
- 7-126: Reservado
- Reservado por ahora, por lo que se podría decir que si un bloque tiene descriptor en este rango, no es valido. Se planea su uso futuro.
- 127: No válido
- Bloque no valido, ya que la misma secuencia se usa cómo marcador para sincronización.
Bloque "STREAMINFO"
- <16> Tamaño mínimo del bloque.
- <16> Tamaño máximo del bloque.
- <24> Tamaño mínimo del "FRAME" en bytes.
- <24> Tamaño máximo del "FRAME" en bytes.
- <20> Frecuencia de sampleo.
- <3> Número de canales.
- <36> Total de muestras por segundo.
- <128> MD5 del audio.
















No hay comentarios. :
Publicar un comentario