Vamos a programar #104 - Leyendo metadatos de archivos FLAC (Pt. 3 Ver. C#)
Hola de nuevo a todos, el día de hoy vamos a continuar con la última parte de FlacTagReader.

En el post anterior vimos cómo es que funcionan algunas funciones (valga la redundancia) y hoy veremos las faltantes.
La siguiente función es: "NumberToBlockType()". Esta función sirve para convertir un número en su equivalente al de la numeración "BlockTypes". Recibe un parámetro del tipo "uint" que es el número que queremos convertir. Regresa un valor del tipo enumeración "BlockTypes" equivalente. Hay que recordar que nos basamos en la de los tipos de bloques de la documentación.
La siguiente función es: "ReadVorbisData()". Cómo su nombre lo podría sugerir, esta función sirve para leer los datos de tipo vorbis ¿Qué es esto? te preguntaras, este bloque en particular es el que contiene los metadatos tales cómo: álbum, artista, año, etc. Siguen la estructura para los comentarios en archivos ogg vorbis.
La estructura de los comentarios es cómo la que sigue:
- Tamaño de la descripción del proveedor (32 bits).
- Cadena de texto para describir al proveedor.
- Tamaño de la lista de comentarios del usuario (32 bits).
- Tamaño de la lista de comentarios.
- Tamaño del elemento actual.
- Cadena de texto en formato UTF-8
- Marcador de final del bloque (si es verdadero o no hay se marca error o fin del bloque).
- Nombre del campo.
- = (símbolo de igual o símbolo ASCII 0x3D).
- Descripción del campo.
- Los nombres de cada campo no deben de contener símbolos que escapen del estándar ASCII de caracteres imprimibles, es decir: de 0x20 a 0x7D (excluyendo el símbolo de igual "=" o 0x3D) y de 0x41 a 0x5A.
- Se pueden usar los siguientes nombres de campo:
- TITLE
- VERSION
- ALBUM
- TRACKNUMBER
- ARTIST
- PERFORMER
- COPYRIGHT
- LICENSE
- ORGANIZATION
- DESCRIPTION
- GENRE
- DATE
- LOCATION
- CONTACT
- ISRC
- Aunque los campos anteriores son sugeridos, podemos usar los propios (sin abusar de ello) y por ejemplo, un campo llamado BEATPERMINUTE, es totalmente válido.

Vamos a programar #103 - Leyendo metadatos de archivos FLAC (pt 2. Ver c#)
Hola de nuevo a todos. El día de hoy vamos a continuar con mas de los archivos FLAC y sus metadatos.

using System; using System.Drawing; using System.IO; using System.Text; using System.Threading; using System.Threading.Tasks; using System.Windows.Forms; namespace FLACTagReader { public partial class Form1 : Form { // 0 : STREAMINFO 0000000 // 1 : PADDING 0000001 // 2 : APPLICATION 0000010 // 3 : SEEKTABLE 0000011 // 4 : VORBIS_COMMENT 0000100 // 5 : CUESHEET 0000101 // 6 : PICTURE 0000110 // 7-126 : reserved 1111000 - Invalid // 127 : invalid, to avoid confusion with a frame sync code /// <summary> /// Enumeración con los posibles bloques contenidos en un archivo FLAC /// </summary> private enum BlocksTypes { /// <summary> /// Bloque mandatorio con la información del Stream /// </summary> Block_Type_StreamInfo = 0, /// <summary> /// Bloque de Padding /// </summary> Block_Type_Padding = 1, /// <summary> /// Bloque con la informacion de la aplicación /// </summary> Block_Type_Application = 2, /// <summary> /// Bloque Seektable /// </summary> Block_Type_SeekTable = 3, /// <summary> /// Bloque con metadatos /// </summary> Block_Type_VorbisComment = 4, /// <summary> /// Bloque con cuesheet /// </summary> Block_Type_CueSheet = 5, /// <summary> /// Bloque con imagen /// </summary> Block_Type_Picture = 6, /// <summary> /// Bloque no válido /// </summary> Block_Type_NoValid = 7 } public Form1() { InitializeComponent(); } /// <summary> /// Crea una imagen a partir de una secuencia de bytes /// </summary> /// <param name="bytesArr">Matriz de bytes que contiene los datos de la imagen</param> /// <returns>Regresa una imagen</returns> public Image ByteArrayToImage(byte[] bytesArr) { using (MemoryStream memstr = new MemoryStream(bytesArr)) { Image img = Image.FromStream(memstr); return img; } } // 4 4 n*4 4 n*4 4 4 4 4 !4 !n*4 //<32>,<32>,<n*8>,<32>,<n*8>,<32>,<32>,<32>,<32>,<32>,<n*8> // 1 2 3 4 5 6 7 8 9 10 11 /// <summary> /// Lee todo los datos del bloque PICTURE y extrae la imagen contenida /// </summary> /// <param name="TheData">Arreglos bytes que contiene todo el bloque PICTURE</param> /// <returns>Regresa una imagen</returns> private Image ReadPictureData(byte[] TheData) { uint CurrentPos = 4;//1 uint CurrentSize = GetBlockSize(TheData, (int)CurrentPos, 4); CurrentPos += 4;//2 string MimeType = Encoding.ASCII.GetString(TheData, (int)CurrentPos, (int)CurrentSize); CurrentPos += CurrentSize;//3 CurrentSize = GetBlockSize(TheData, (int)CurrentPos, 4); CurrentPos += (CurrentSize + (4 * 5));//4-9 CurrentSize = GetBlockSize(TheData, (int)CurrentPos, 4); CurrentPos += 4; byte[] TempImage = new byte[CurrentSize]; Array.Copy(TheData, CurrentPos, TempImage, 0, CurrentSize); return ByteArrayToImage(TempImage); } /// <summary> /// Convierte un número en su valor equivalente al tipo de bloque /// </summary> /// <param name="Data"> /// Entero sin signo con la representacion del bloque</param> /// <returns>Regresa un valor de la enumeración <typeparamref name="BlockTypes"/>BlockTypes</returns> private BlocksTypes NumberToBlockType(uint Data) { switch (Data) { case 0: return BlocksTypes.Block_Type_StreamInfo; case 1: return BlocksTypes.Block_Type_Padding; case 2: return BlocksTypes.Block_Type_Application; case 3: return BlocksTypes.Block_Type_SeekTable; case 4: return BlocksTypes.Block_Type_VorbisComment; case 5: return BlocksTypes.Block_Type_CueSheet; case 6: return BlocksTypes.Block_Type_Picture; default: return BlocksTypes.Block_Type_NoValid; } } /// <summary> /// Lee el bloque con la informacion estructurada /// </summary> /// <param name="TheData">Arreglo de bytes del cual se extraera la información</param> /// <returns>Regresa un arreglo del tipo string con todos los campos que se encontraron</returns> private string[] ReadVorbisData(byte[] TheData) { uint NumberOfFields = 0; uint CurrentField = 1; uint CurrentPosition = 0; //Vendor uint CurrentSize = BitConverter.ToUInt32(TheData, (int)CurrentPosition); CurrentPosition += 4; byte[] CurrentChunk = new byte[CurrentSize]; Array.Copy(TheData, CurrentPosition, CurrentChunk, 0, CurrentSize); string Currenttext = Encoding.UTF8.GetString(CurrentChunk); CurrentPosition += CurrentSize; NumberOfFields = BitConverter.ToUInt32(TheData, (int)CurrentPosition); CurrentPosition += 4; string[] Fields = new string[NumberOfFields]; //CommentField while (CurrentField <= NumberOfFields) { CurrentSize = BitConverter.ToUInt32(TheData, (int)CurrentPosition); CurrentPosition += 4; byte[] CurrenUserCommentList = new byte[CurrentSize]; Array.Copy(TheData, CurrentPosition, CurrenUserCommentList, 0, CurrentSize); Currenttext = Encoding.UTF8.GetString(CurrenUserCommentList); CurrentPosition += CurrentSize; Fields[CurrentField - 1] = Currenttext; CurrentField += 1; } return Fields; } /// <summary> /// Obtiene el valor del bloque desde un byte /// </summary> /// <param name="Data">byte del cual se va a obtener la información</param> /// <returns>Regresa un valor que es equivalente al tipo de bloque</returns> private UInt32 GetBlockType(byte Data) { Data <<= 3; Data >>= 3; return Data; } /// <summary> /// Obtiene si el bloque es el último de la serie /// </summary> /// <param name="Data">byte del cual se obtendra la información</param> /// <returns>true si el bloque es el último, false en caso contrario</returns> private bool IsLastFrame(byte Data) { Data >>= 7; if (Data == 1) return true; else return false; } /// <summary> /// Obtiene el tamaño de un bloque /// </summary> /// <param name="Data">Arreglo de bytes que contiene el tamaño del bloque</param> /// <param name="StartIndex">Indica la posicion en donde se empezará a leer</param> /// <param name="Size">Indica el tamaño en bytes que se van a leer</param> /// <returns>Regresa el tamaño del bloque actual</returns> private UInt32 GetBlockSize(byte[] Data, int StartIndex, int Size) { byte[] CurrentData = new byte[4]; Array.Copy(Data, StartIndex, CurrentData, 0, Size); Array.Reverse(CurrentData); return BitConverter.ToUInt32(CurrentData, 0); } /// <summary> /// Obtiene el tamaño de un bloque /// </summary> /// <param name="Data">Arreglo de bytes que contiene el tamaño del bloque</param> /// <returns>Regresa el tamaño del bloque actual</returns> private UInt32 GetBlockSize(byte[] Data) { byte[] CurrentData = Data; //Ponemos el primer byte en 0 porque se usa para identificar el bloque //a la hora de convertir a UInt32 se esperan 4 bytes, pero este siempre será 0 u otro valor no relevante //para el tamaño del bloque CurrentData[0] = 0; Array.Reverse(CurrentData); return BitConverter.ToUInt32(CurrentData, 0); } /// <summary> /// Obtiene los datos de un bloque /// </summary> /// <param name="FileName">Nombre del archivo del cual se obtendra</param> /// <param name="TypeOfBlock">Tipo de bloque que se va a buscar</param> private void GetBlock(string FileName, BlocksTypes TypeOfBlock) { byte[] DataBuff; bool LastFrame = false; FileStream FS = new FileStream(FileName, FileMode.Open, FileAccess.Read, FileShare.Read); using (BinaryReader BR = new BinaryReader(FS, Encoding.ASCII)) { DataBuff = BR.ReadBytes(4); if (string.Equals(Encoding.ASCII.GetString(DataBuff), "fLaC", StringComparison.Ordinal)) { UInt32 CurrentBlockSize; UInt32 CurrentPosition = (UInt32)FS.Position; BlocksTypes CurrentBlockType = BlocksTypes.Block_Type_NoValid; while (!LastFrame) { //primer bloque siempre será Block_Type_StreamInfo DataBuff = BR.ReadBytes(4); LastFrame = IsLastFrame(DataBuff[0]); CurrentBlockType = NumberToBlockType(GetBlockType(DataBuff[0])); if (CurrentBlockType == TypeOfBlock) { if (TypeOfBlock == BlocksTypes.Block_Type_VorbisComment) { string[] Fields; CurrentBlockSize = GetBlockSize(DataBuff); Fields = ReadVorbisData(BR.ReadBytes((int)CurrentBlockSize)); textBox1.Clear(); for (int i = 0; i < Fields.Length; i++) { textBox1.Text += Fields[i] + " | "; } } else if (TypeOfBlock == BlocksTypes.Block_Type_Picture) { CurrentBlockSize = GetBlockSize(DataBuff); pictureBox1.Image = ReadPictureData(BR.ReadBytes((int)CurrentBlockSize)); } } else { CurrentBlockSize = GetBlockSize(DataBuff); FS.Seek(FS.Position + CurrentBlockSize, SeekOrigin.Begin); } } } else { MessageBox.Show("Archivo Flac no válido"); } } } private void button1_Click(object sender, EventArgs e) { using (OpenFileDialog OpDiag = new OpenFileDialog()) { OpDiag.Filter = "Archivos FLAC|*.flac|Todos los arhivos|*.*"; if (OpDiag.ShowDialog() == DialogResult.OK) { GetBlock(OpDiag.FileName, BlocksTypes.Block_Type_VorbisComment); GetBlock(OpDiag.FileName, BlocksTypes.Block_Type_Picture); pictureBox1.SizeMode = PictureBoxSizeMode.StretchImage; } } } } }
- <32> El tipo de imagen de acuerdo a la descripción de la etiqueta ID3 "APIC".
- <32> El tamaño de la descripción del tipo de archivo o MIME type.
- <n*8> Cadena de texto con la descripción del tipo de archivo.
- <32> El tamaño de la descripción de la imagen.
- <n*8> La descripción de la imagen en UTF8
- <32> El ancho de la imagen en píxeles
- <32> El alto de la imagen en pixeles.
- <32> La profundidad del color de la imagen en bits por pixel.
- <32> Para las imágenes con índice de color, el número de colores usados, para el resto 0.
- <32> El tamaño de los datos de la imagen.
- <n*8> Los datos de la imagen.

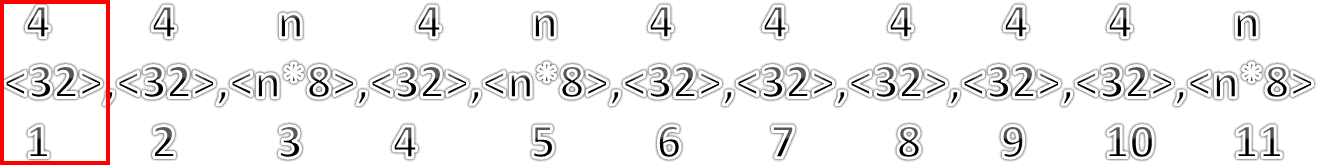




Vamos a programar #102 - Leyendo metadatos de archivos FLAC (pt.1)
Hola de nuevo a todos. El día de hoy vamos a continuar con más de los archivos FLAC.

En los post mas recientes hemos visto las cualidades de los archivos FLAC, pero además cómo crear los nuestros. Al igual que en MP3, existen metadatos embebidos en ellos, y sirven para describir algunos datos importantes tales cómo: el nombre de la canción, el artista, el nombre del álbum, el genero, etc.
Estructura de un archivo FLAC
La estructura de los archivos FLAC es totalmente diferente a la de un MP3 por lo que vale la pena revisarla por separado. Cada archivo FLAC consiste de cuatro partes principales:
- Una cadena de cuatro bytes con la secuencia "fLaC" (así tal cual se ve).
- Un bloque de metadatos con la información del "stream"
- Cero o mas bloques de metadatos.
- Uno o mas "frames" de audio.
Para mas detalles se puede revisar la página de xiph.org, donde esta la descripción completa para los archivos FLAC.
De las cuatro partes que se mencionan anteriormente, nos concentraremos en la segunda y tercera (Técnicamente las dos entran en el mismo conjunto, solo que la segunda es obligatoria, mientras que las subsecuentes son opcionales, hablando solamente de los bloques de metadatos), por lo que revisaremos cómo es que está compuesta cada una.
Pero antes una representación de cómo está estructurado el archivo:

Metadatos
- STREAM
- METADATA_BLOCK
- METADATA_BLOCK_HEADER (Encabezado)
- <1> Indicador de último bloque
- <7> Descriptor del tipo de bloque
- <24> Tamaño del bloque en bytes (BYTES!!!)
- 0: STREAMINFO
- Contiene información acerca de todo el archivo, este bloque es mandatorio y siempre será e primero de la secuencia después de la secuencia 0x66, 0x4c, 0x61, 0x43 (o de manera simple después de "fLaC" ).
- 1: PADDING
- Este tipo de bloque sirve cómo reserva y el contenido no representará nada, normalmente se llena con 0x00. Cuando se crea el archivo sin los metadatos completos, en lugar des escribir un archivo nuevo con los bloques nuevos, simplemente se reemplaza este bloque conservando el archivo original y agilizando la escritura del mismo.
- 2: APPLICATION
- Nombre de la aplicación que se uso para codificar el archivo, puede ser cualquiera que el usuario elija, aunque se recomienda el registro de la aplicación para obtener un ID único para cada quien.
- 3: SEEKTABLE
- Sirve cómo marcador para desplazarse en el archivo a la hora de la reproducción, aunque se puede omitir, se recomienda incluirlo para agilizar la lectura.
- 4: VORBIS_COMMENT
- Este bloque contiene la información relevante a los creadores del contenido multimedia y la descripción del mismo, se usa la especificación de "Vorbis comment"
- 5: CUESHEET
- Contiene información que se puede usar en un CD
- 6: PICTURE
- Imagen representativa del archivo, similar a la imagen embebida en un archivo MP3.
- 7-126: Reservado
- Reservado por ahora, por lo que se podría decir que si un bloque tiene descriptor en este rango, no es valido. Se planea su uso futuro.
- 127: No válido
- Bloque no valido, ya que la misma secuencia se usa cómo marcador para sincronización.
Bloque "STREAMINFO"
- <16> Tamaño mínimo del bloque.
- <16> Tamaño máximo del bloque.
- <24> Tamaño mínimo del "FRAME" en bytes.
- <24> Tamaño máximo del "FRAME" en bytes.
- <20> Frecuencia de sampleo.
- <3> Número de canales.
- <36> Total de muestras por segundo.
- <128> MD5 del audio.






El Video (AUDIO) Correcto #9 - Convirtiendo CD a FLAC
Hola de nuevo a todos, el día de hoy vamos a ver cómo extraer nuestros audios de CD's originales y convertirlos a FLAC. Al inicio pensé en hacer alugan clase de programa para hacerlo, pero cómo probablemente solo uno de cada mil personas va a convertir sus discos (incluso a estas alturas, habrá quienes no los conozcan), decidí solo mostrar cual es el método que uso actualmente.

Para poder hacer la copia de los discos, vamos a usar MediaGo de SONY, aunque es un programa relativamente viejo, aun al día de hoy funciona y tiene la virtud de que las funciones que requieren de internet, aun funcionan. Para no adelantarnos, vamos a ir en orden y lo primero que haremos es descargar el instalador de Media Go. Una vez lo descargamos, lo instalamos y lo ejecutamos.
Una vez que el programa está listo, simplemente insertaremos nuestro CD. De lado izquierdo aparecerá en una ficha llamada "CD de audio"; hacemos clic en ella y podremos ver el contenido del CD.

Antes de continuar, haremos clic en el menú "Herramientas>>Preferencias" y se abrirá un dialogo con los ajustes del programa.

Hacemos clic en "Importación de CD" y en la caja de selección de la opción "Usar pistas usando el formato" seleccionaremos la opción FLAC. Hacemos clic en aceptar y los ajustes estarán listos.
Para comenzar la copia, simplemente hacemos clic en el botón "Importar CD". La copia comenzará y al finalizar, podremos escuchar nuestro archivos.

La razón principal para usar "Media Go" es simple: Ya tiene todo lo necesario; cuando importa los archivos, se conecta a la base de datos Gracenote y obtiene todos los datos que puedan ser relevantes a la hora de identificar una canción.
Y bien, por ahora es casi todo...
He hablado de las cosas que son necesarias para poder oír audio en buena calidad (y no hablo de esos "audiofilos mugorosos" que le rebanan los bordes al los CD's para mejorar la calidad del audio), ya mencione los audifonos, los archivos de audio y la última cosa que es importante mencionar; y eso es el dispositivo que se va a encargar de reproducir el archivo.
Muchos de los celulares, simplemente contienen la "placa de audio" mas genérica que se pude encontrar, aun en los dispositivos de gama media, la mayor parte de ellos tendrán dicha placa que solo es capaz de reproducir hasta 32000Hz (si bien nos va); aunque parezca redundante; si conectamos unos audífonos de calidad superior al puerto 3.5mm del teléfono y este solo pude decodificar hasta cierta calidad, estaremos desperdiciando el hardware. Identificar si un teléfono es capaz de reproducir audio en alta calidad no es sencillo, ya que muchas veces es un dato que no es relevante a la hora de vender (siempre se verá primero la RAM y el CPU) pero si es posible, buscar el logotipo "Hi res audio" ayuda.
Aun si el equipo no cuenta con el logotipo, hay otras formas de saber si lo es.
 |
| LDAC ayuda a transmitir audio en alta calidad por Bluetooth |
Y bien, por ahora es todo, en el siguiente post veremos cómo leer los metadatos de los archivos FLAC en C# y varios lenguajes mas.
Los leo luego.
El Video (AUDIO) Correcto #8 - WAV VS FLAC
Hola de nuevo a todos, el día de hoy vamos a continuar con un poco más sobre el audio de buena calidad.

En el post anterior vimos cómo es importante tener un par de audífonos de la calidad adecuada para poder disfrutar de la música cómo es debido. Pero, no solo se trata de los audífonos, hay otros elementos que son importantes a la hora de disfrutar del audio de buena calidad.
En este post nos concentraremos en el archivo de audio en si. En reiteradas ocasiones he dicho que los archivos FLAC ofrecen una calidad superior al MP3, incluso en alguno de los post anteriores hice el comparativo, en twitter (o ahora X), mucha gente dijo que los archivos FLAC si bien tienen una calidad mejor que el MP3, también se pierde mucha de la información que conforma la música, y esto es cierto o no, dependiendo de cómo se configura la compresión, cual es el origen del cual vamos a crear nuestro FLAC y algunos otros factores. Pero por lo general, si se configura bien, los archivos FLAC no tendrán ninguna perdida y para probarlo, vamos a hacer la misma prueba que hicimos hace tiempo; vamos a comparar FLAC contra WAV. ¿Por qué WAV? te estarás preguntando, simple, es el contenedor que se usa para el audio sin compresión, por lo que su tamaño será significativamente mayor al de los otros.
 |
| Archivo WAV copiado desde un CD ORIGINAL |
 |
| Archivo FLAC creado desde un CD ORIGINAL |
Las pruebas.

El Video (AUDIO) Correcto #7 - Un poco mas sobre el audio.
Hola de nuevo a todos, el día de hoy vamos a ver un poco mas sobre los archivos FLAC.
 |
| imagen tomada de: https://www.revistagadgets.com/2017/04/04/audio-hi-res-la-nueva-linea-audifonos-pioneer/ |
Cómo muchos de ustedes sabrán, me gusta mucho oír música (música de verdad y no "regeton"), pero siempre había usado equipo de "baja calidad" (y solo por nombrarlo de alguna manera). Pero no hace mucho tiempo, visité un lugar donde se exponían diferente sistemas de audio, desde los mas sencillos; cómo bocina bluetooth; hasta los mas complejos; llámese audio de estudio.
Dentro del mismo lugar había un apartado para los audífonos, de inmediato fui a revisar, y había varios para probar. Cada uno tenia la ficha que describía cuales eran sus características, pero hacían un fuerte énfasis en la frecuencia de respuesta de cada uno.
Primero probé los que ofrecían una respuesta de 20 hasta 20000Hz, justo cómo la mayor parte de audífonos son, la calidad era aceptable, mucho de los audífonos que he tenido cumplían con esa frecuencia y todo parecía aceptable. Los siguientes tenían una respuesta de 20 hasta 32000Hz, la misma calidad que los audífonos que siempre usaba, y justo cómo los anteriores, todo funcionaba bien, y a mi gusto, nada podía superar la calidad. En la siguiente mesa había unos audífonos con una respuesta de 20 hasta 40000Hz... había vivido engañado todo el tiempo, siempre me habían dicho que el oído humano no era capaz de oír frecuencias mas allá de los 32000Hz, pero al momento de probar esos, de inmediato me di cuenta que, si bien es cierto que el oído humano está limitado a ciertas frecuencias, el hecho es que cada persona es diferente y hay quienes alcanzan un rango auditivo mayor al de otros. En mi caso es muy difícil decir hasta "donde puedo escuchar", ya que nunca he hecho un estudio que sirva para eso, pero no había duda de que esos audífonos "sonaban mejor" que los otros, por lo que decidí conseguir unos.
Finalmente cosegui unos audifonos edifier w820nb plus que cuestan poco y tienen la calidad superior a los que ya tenía.


Cumplimos 7 años -_-!!!!

En tiempos recientes, he tenido que atender otros asuntos y contrario a lo que se podria pensar, basados en el estado del blog; realmente estoy disfrutando el momento y por eso es que lo he descuidado, pero cómo todo, estoy tratando de encontrar el balance entre haer lo que debo y lo que me gusta (que casí van de la mano).
Por eso nuevamente quiero agradecer a todos los que visitan y recordarles que sigan al pendiente que esto seguirá mientras no haya ningun impedimento.
 |
| Hay varios proyectos listos, solo hay que esperar un poco |
Saludos y nos seguimos leyendo.
Vamos a programar #101 - Operaciones a nivel de bits en Python y tablas de verdad.
Hola de nuevo a todos, el día de hoy vamos a ver mas operaciones a nivel de bits.

Hace algunos días alguien me pregunto que si era posible usar operaciones a nivel de bits en Python, la respuesta sencilla es: si. Pero ¿Cómo es que trabaja cada una y cuales son las que están disponibles? Anteriormente vimos cómo es posible usarlos en C# y si bien son esencialmente lo mismo, vale la pena revisarlas por separado. En este post veremos las operaciones disponibles SOLO para Python.
En Python disponemos de las siguientes operaciones:
- Or (o) "|"
- XOr (o exclusivo) "^"
- And (y) "&"
- Shift left (desplazamiento a la izquierda) "<<"
- Shift right (desplazamiento a la derecha) ">>"
- Not (inverso) "~"
Or "|"
- Verdadero O Verdadero = Verdadero
- Verdadero O Falso = Verdadero
- Falso O Verdadero = Verdadero
- Falso O Falso = Falso
- 1|1 = 1
- 1|0 = 1
- 0|1 = 1
- 0|0 = 0

XOr "^"
- Verdadero OEx Verdadero = Falso
- Verdadero OEx Falso = Verdadero
- Falso OEx Verdadero = Verdadero
- Falso OEx Falso = Falso
- 1^1 = 0
- 1^0 = 1
- 0^1 = 1
- 0^0 = 0

And "&"
- Verdadero Y Verdadero = Verdadero
- Verdadero Y Falso = Falso
- Falso Y Verdadero = Falso
- Falso Y Falso = Falso
- 1&1 = 1
- 1&0 = 0
- 0&1 = 0
- 0&0 = 0

Shift Left "<<"
- 76 << 2 = 304
- 1001100 << 10 = 100110000
MiNum = 76
print (MiNum)
print("{:b}".format(MiNum))
MiNum <<= 0b10
print(MiNum)
print("{:b}".format(MiNum))
Shift Right ">>"
- 76 >> 4 = 4
- 1001100 >> 100 = 100
MiNum = 76
print (MiNum)
print("{:b}".format(MiNum))
MiNum >>= 0b100
print(MiNum)
print("{:b}".format(MiNum))
Not "~"
Inútil apps #5 - Visualizer V3 (parte 3)
Hola de nuevo a todos, después de tomar el sueño eterno (que en la actualidad es de seis a nueve meses!!) Por fin regresamos a terminar con los asunto pendientes y a tratar de aprender mas en el proceso. En el último post, estábamos fabricando unas luces que prenden y apagan al ritmo de la música.

| MARCA | Valor |
|---|---|
| R1,R4,R9,R10 | 10k |
| R2,R5 | 1k |
| R3,R6 | 200k |
| R7,R8 | 680 |
| C1,C2 | 10uF |
| D1,D2 | 1N4007 |
| U1 | LM358 |
| U2,U3 | LM3915 |
| LED1,LED2,LED3,...,LED20 | Diodo LED 5mm |
| POT1 | Potenciómetro 100k |
| BUCK1 | Buck converter |

- AUDIOINR
- Sirve para conectar el audio, el canal derecho es recomendado, en el pin que tiene forma de cuadrado o PIN1 conectamos la parte positiva del audio, el pin 2 no se conecta y el pin 3 va al negativo del audio.
- AUDIOINL
- Igual que el anterior, sirve para conectar el audio de entrada, el canal izquierdo es el recomendado.
- H1
- Comparte las conexiones del pin 1 y tres de los pines "AUDIOINR", pero además, en este se encuentra la salida regulada del audio que se conecta a una entrada del LM358.
- H2
- Comparte las conexiones del pin 1 y tres de los pines "AUDIOINL", pero además, en este se encuentra la salida regulada del audio que se conecta a una entrada del LM358.
- H3
- Es la entrada de 5v
- H4
- Es la entrada de 12v
- U5 y U4
- Son los jumpers para seleccionar el modo punto o barra del LM3615












No hay comentarios. :
Publicar un comentario